Monitor behaviours, not states
Is it possible to reduce the number of tests suite, and at the same time reach a better level of observability and increase our confidence through all the different parts of our systems?
The following is an idea I had regarding testing and monitoring software, it is my intent to share here some of my thoughts with you and I am wishing to listen to your opinion.
Common trends in testing and monitoring
From what I have seen, and based on my experience in the software industry, the common trend in testing and monitoring is to invest a lot of effort in creating a dedicated suite of tests based on specific purposes.
Let me provide a few examples:
-
A suite of acceptance tests because we want to be sure that the business requirements are satisfied. We do usually run them just before pushing code changes, or we run them against a production-like environment to verify that newly introduced changes are working correctly with all the integrations in place, and no regressions have been introduced.
-
A suite of load or performance tests because it may happen we want to understand how our system behaves under certain circumstances, such as multiple and concurrent users, heavy load, or other specific cases.
-
A suite of synthetic tests that periodically run against a production instance to catch errors earlier. This is often a limited set of tests, also known as smoke tests.
Flavors of software
I am quite sure we are still creating several other specific tests suite for the most desperate use cases, while at the same time creating duplication between:
- Backend
- Frontend
- Android (smartphone, tablet, TV)
- iOS (smartphone, tablet, TV)
- Other …
I am talking about duplication since the very same feature of the backend that is used by a frontend is tested twice. You have a tests suite for the backend and you have a tests suite for the frontend.
Observability and noise
On the other hand, we also instrument our code to check the state of each single service and each single request, and we configure alarms to be triggered when something bad happens.
Bear with me, I am not saying that these kinds of tools are bad. On the contrary, they are really important.
But in the very end, we often find ourselves in a situation where a great variety of tools are used to keep the observability of our services high.
And at the same time, regardless of the amount of effort we invest in a specialized suite of tests, code instrumentation, alarm and notification systems, and logging, we hardly can tell what is really happening in production:
- Are all the features working correctly?
- What’s the business impact of each single feature?
- How do we have to react if a specific feature stops working?
- What are the most used and the less used features?
- How the users are - really - using our systems?
What about logging and metrics?
These are invaluable tools. I am not proposing the replace them.
We need tools to collect metrics and logs throughout the system. These tools can tell us what part of the system is working and not.
We can tell what requests are failing, which ones are responding slowly, and easily spot the reasons: slow database queries, third-party services down, queue system is stuck, and whatever happens.
Being able to trace the error down to the root of the problem, is a must-have for troubleshooting.
But these tools hardly can tell what features have been impacted by a specific error. This is what a synthetic monitor can tell in conjunction with tools for logging and metrics.
We can now tell that a malfunctioning third-party service had an impact on features A, B, and C of the system for the last 24 minutes.
It’s not a new tool or technique
I am not writing this blog to propose a new suite of specialized tests, instead I am proposing a clean-up, and replace all the test suite with a single, authoritative and reliable suite of tests that describe each feature and the exact behavior we expect to see through the system.
Duplication! Duplication everywhere!
I came to the conclusion that the differences between all these specialized test suite, it’s not to be found in what they describe. It’s to be found on the way they run.
The “test runner” is the changing part. Not the whole test suite.
We do usually tend to have a duplication in terms of tests between a mobile and web application since we write two different test suite that basically are describing the same feature. The same can happen between frontend and backend. Again, it happens for Load Tests and Acceptance Tests.
Duplication is often a synonym for bad maintainability, and can easily lead to errors.
We might forget to update the load tests suite for a newly introduced feature; we might miss to update a synthetic test in production, and so on.
One test suite, multiple ways of running it
Describe your feature once. Run it multiple ways.
It’s my intention to provide a real-life example where the features are described only once, and then ran in different ways based on the system under test. In such a way to run the feature against a backend, or a specific client (frontend, mobile, or whatever) and also, with different setup (e.g. a test runner configured to run a load test.)
Here below I made an illustration to provide a visual representation of what I am talking about:
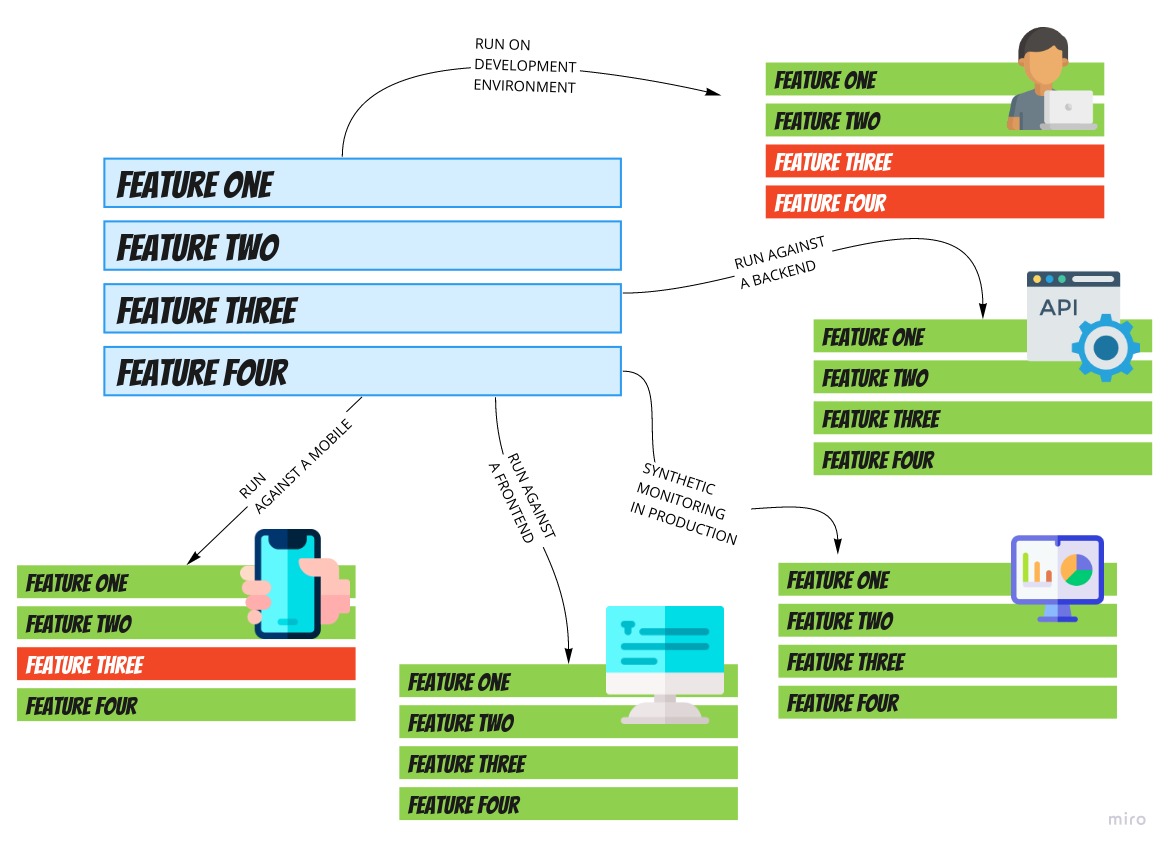
In this picture we can see:
- The same test suite is running against the mobile application and found that feature three is not working.
- The same test suite is running as a synthetic monitor, providing a real-time dashboard with the of each single feature.
- The same test suite is running in a local development to help the developer catch regressions early.
- The same test suite is running against the backend services and the frontend application.
What’s your feedback?
With this blog post, I wanted to propose an idea for:
- Having no duplication across several tests suite we might want to have.
- Having a better observability of your system in production, on what feature is working and not.
- Reaching an observability parity between systems (web app, mobile, backend, TV).
- Describing your features once and run in multiple ways.
I am willing to continue exploring this topic and propose a simple real-life application that can be used as a reference implementation.
What’s your opinion? Do you like the idea?
If you want to share your story or give your feedback, feel free to reach me on Twitter.