Growing systems towards DDD, Event-Sourcing and Event-Driven architecture
This article explores how software systems can grow from simple MVC Applications, toward Domain-driven Design, Event-Sourcing, and Event-Driven, in an incremental way. It highlights how these concepts can stay decoupled, and show how Application Services defines transactional boundaries.
I want to summarize some of my insights from my previous work experiences and studies on DDD, Event-Sourcing, and Event-Driven architectures, and more recently, from a book club ran together with Pietro Di Bello and Matteo Pierro on the book Exploring CQRS and Event Sourcing.
If you are working with Domain-Driven Design (DDD) and/or CQRS/Event-Sourced systems, you are familiar with the challenge of publishing events when changes occur at the aggregate level. This is one of the most common aspects of event-driven systems, yet there are multiple ways to approach it, each with its own trade-offs.
Before we dive in…
Whether you are new to these topics or already familiar with them, I would like to clarify a few key aspects:
- This article shares a practical approach to combine topics like Domain-Driven Design, Event-Sourcing, and Event-Driven when all present in the same code base - even though they are conceptually separate.
- Event-Sourcing is rarely a strict need. - Most of the time, a well-structured relational database with a few good tables will do the job just fine.
- Domain-Driven Design is not CQRS/Event-Sourcing. - While they often appear together, they serve different purposes.
- Event-Sourcing is NOT Event-Driven. - Event-Sourcing uses events to persist state. Event-Driven supports the need for asynchronous and decoupled communication between systems. Event Sourcing and Event-Driven have different purposes and the type of events are also different.
Keeping this in mind will help to set the right context for this article, because during my studies I tried to blend aspects like DDD, Event-Sourcing and Event-Driven together, and I hope, this can help to provide a clearer implementation of such systems, and also a few hints to think about if you are considering pursuing the journey towards these topics.
… Let’s continue
Let’s take a look at a typical flow of a use case in a codebase where Domain-Driven Design, Event-Sourcing, and Event-Driven are all present:
- A client interacts with an application service (or command handler), triggering a request.
- The corresponding aggregate is loaded from the event store (or repository).
- The aggregate executes the action: business invariants are checked, a new event is applied, and the state is modified.
- The aggregate is persisted, and the resulting events are published somewhere.
In short
Application Service → Aggregate Change → Event Publishing
There are multiple ways to implement this, each with its own trade-offs. I can mention a few, and I hope some of them can resonate with any of your experiences:
- Event Store as Publisher – The aggregate is loaded from the event store, changes are persisted, and the event store itself takes responsibility for publishing events.
- Aggregate as Publisher – The aggregate publishes the events directly, ensuring that event generation is coupled with business logic.
- Repository as Publisher – The event store remains an implementation detail of the repository, and the repository itself is responsible for event publishing.
- Application Service as Publisher – Events are explicitly published at the application service level (or command handler).
Each approach is valid, and the desidered one depends on the needs and the familiarity of the people that are working on such systems. I will not dig into the trade-offs of any of the suggested approaches though.
Instead, I would like to start from personal reflections and share with you a possible alternative approach, and why in my opinion can result in a overall better design of your code.
Software systems grow over time
Software systems grow over time. You might start without DDD, Event-Sourcing, or Event-Driven architecture, and that is perfectly fine. As the system evolves, you may gradually find yourself in the need to refactor towards DDD, adopt Event-Sourcing for state persistence, or start publishing events to communicate with other parts of the system.
That is the key idea behind this article. I want to illustrate how systems can grow over time in this direction, how they can evolve in a decoupled way, and why there is no single “correct” order to follow, as you refactor your code in that growth.
My goal is to keep this article as practical as possible and provide a reference example of how a system can grow towards DDD, Event-Sourcing, and ultimately Event-Driven architecture (the order is of my preference, but you can try to grow the system starting from another point, based on your needs).
![]() Before we move on, I want to remind you once again that you should read the content presented in this article as a reference example, and not something you can copy and paste into your codebase. There are several things I have deliberately skipped, and the example code is overly simplified, to keep the focus on the most important parts of the flow.
Before we move on, I want to remind you once again that you should read the content presented in this article as a reference example, and not something you can copy and paste into your codebase. There are several things I have deliberately skipped, and the example code is overly simplified, to keep the focus on the most important parts of the flow.
I am considering open-sourcing a more complete sample code on GitHub (possibly implemented in different programming languages). I think this could be a great help to familiarize with these topics. For convenience, the code shown in this article will be Ruby.
0. Starting code
Let’s start with a simple, familiar piece of code. No DDD, no Event-Sourcing, no Event-Driven yet.
The following is a code from a hypothetical application for an “Order Taking System”, in which the functionality of revoking an order is part of a controller (controller as an MVC-based web framework, like Rails, or similar).
class orders_controller
def revoke
order = Order.find(params[:order_id])
order.update(revoked_at: Time.zone.now)
render plain: "Order revoked", status: :ok
end
end
1. Towards DDD
As we start refactoring towards DDD, we begin to introduce concepts like Application Services, Repositories, and Aggregates. In this case, the logic for revoking an order is moved into an application service (RevokeOrder), the actual details are encapsulated within the aggregate (Order), and moved away from direct usage of an ORM, introducing a repository (Orders) to provide a clear separation for persistence:
class RevokeOrder
def self.call(order_id)
order = Orders.find(order_id)
order.revoke
Orders.save(order)
end
end
The RevokeOrder application service can now be called from within the controller (or elsewhere in the code base):
class orders_controller
def revoke
RevokeOrder.call(params[:order_id])
render plain: "Order revoked", status: :ok
end
end
2. Towards Event-Sourcing
When I think about Event-Sourcing, I always want to remind myself that it is a persistence mechanism and therefore, from a DDD perspective, it should be considered an implementation detail of the Repository. Clients should not be aware of the underlying system used to store the data and we should be able to change the repository implementation at will, with no impact on the code design:
class RevokeOrder
def self.call(order_id)
order = Orders.find(order_id)
order.revoke
Orders.save(order)
end
end
On the surface no changes can be noticed, but something happened: the Orders repository is now implemented via Event-Sourcing; and this requires some changes in the order aggregate: a way for the aggregate to expose the resulting changes caused by the revoke action. The changes will be used by the repository to persist the new state as a series of events in the event store.
Trade-off: The objection raised here is that we are slightly modifying the Aggregate (a domain component) to fulfill a persistence need (implementation detail).
But again, exposing changes from the aggregate is not unique to Event-Sourcing. It could be useful even in a traditional system for auditing, logging, or notifying external systems. This is an important point I want to emphasize, because it shows how decoupled these parts can be.
Exposing the resulting changes in the order aggregate can be seen as follow:
> changes = order.changes
> [<OrderRevoked>, ...]
And a simplified implementation of an Event-Sourced Orders repository:
class EventStoreOrders < Orders
def save(order)
events = to_events(order.changes)
EventStore.append_to_event_stream(order.id, events)
end
end
And a possible other usage of the changes outside the scope of the persistence, an audit system:
class RevokeOrder
def self.call(order_id)
order = Orders.find(order_id)
order.revoke
Orders.save(order)
Audit.record_changes(order.changes)
end
end
3. Towards Event-Driven architecture
When it comes to event-driven architecture we need to find a way to publish a message somewhere, as result of a change happened, so that other parts of the system can be notified, and eventually, new processes are triggered.
One key aspect of this design I want to highlight in this article is to explictly identify the Transactional Boundary as defined as part of the Application Service, to not be confused with Consistency Boundary or Aggregate Business Invariants.
What follows is an example of how we can describe the atomicity of the Application Service - everything inside either succeeds or fails together, all or nothing:
class RevokeOrder
def self.call(order_id)
within_transactional_boundary do
order = Orders.find(order_id)
order.revoke
Orders.save(order)
EventPublisher.publish(order.changes)
end
end
end
The Application Service defines the Transactional Boundary
I like to think of the Transactional Boundary as:
“Everything that happens inside the Application Service, stays inside the Application Service.”
In other words, the Application Service defines the scope of the operation, and it should guarantee that everything within it happens atomically and consistently: if something fails, the whole operation is rolled back, unless this is intentional.
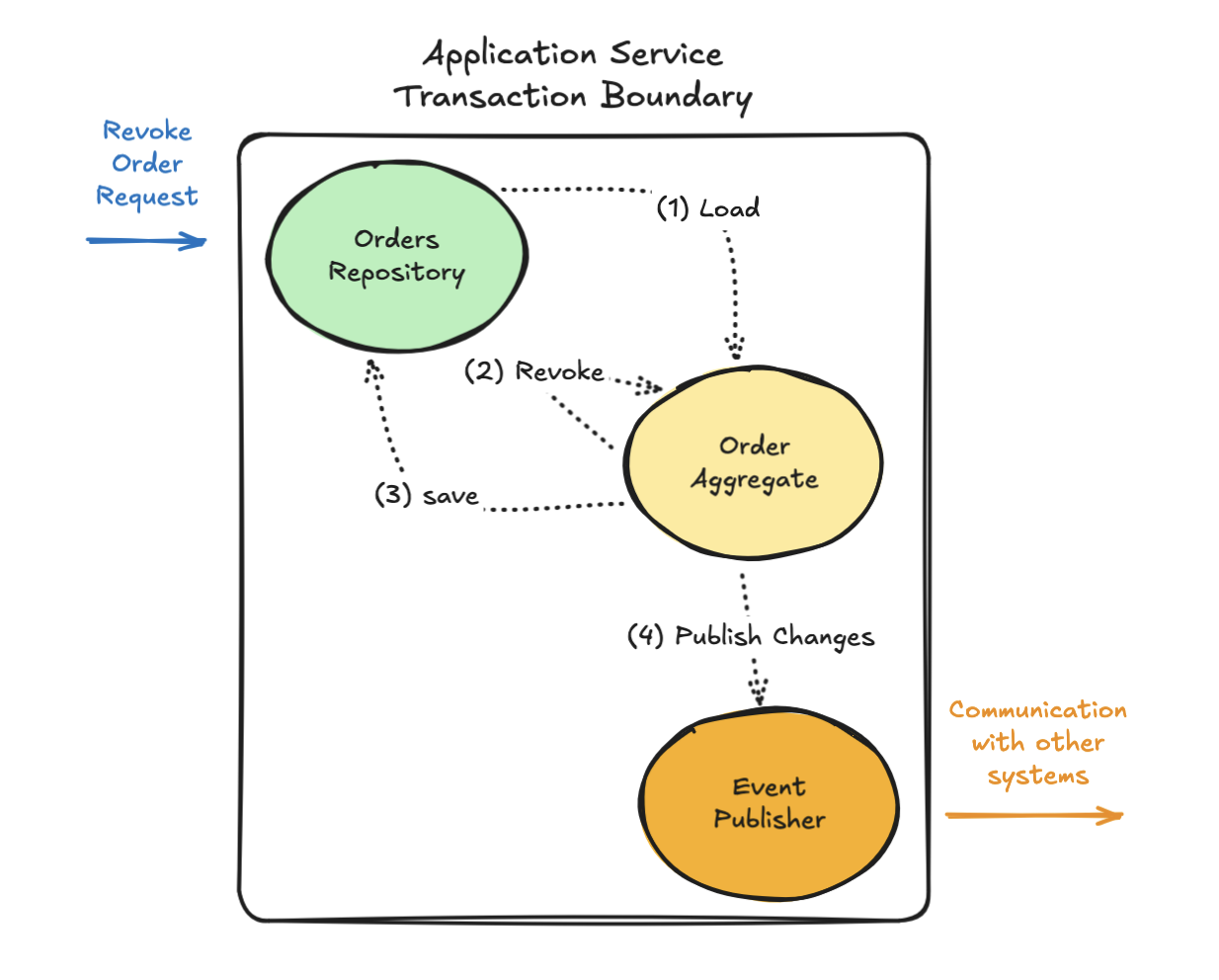
Fig. 1 - Interactions within the transactional boundary.
Differences between Change and Event
You might have noticed I am using the terms Change and Event, and that is deliberate. I want to make a clear distinction between a Change (as something we expect to happen as the result of an action) and an Event (a fact that has been persisted, meaning it actually already happened). Until persisted, an Event is just a Change we expect to see happen.
A Change and an Event are two different things, serving distinct purposes and potentially having different structures. For simplicity, I have kept their implementation mostly the same in this article, the only real difference is that an Event has its own ID, because persisted.
Think of a Change as the intention to revoke an order. It would become an Event only once that intent has been fulfilled, and recorded.
Wrapping-up and Takeaways
We have walked through how a system can grow from a simple MVC application, toward Domain-Driven Design, Event-Sourcing, and Event-Driven architecture. Even though these topics are often mentioned together, they don’t have to be applied all at once, or even at all. They serve different purposes and solve different needs.
Takeaways
- Start simple. There is no need to start your system with DDD, Event-Sourcing, or Event-Driven. Consider to let the system grow as the needs become clear.
- DDD helps to better picture the business domain into your code. Particularly when things starts to grow.
- Event-Sourcing is a persistence mechanism. It changes how you store and load the state, but it should not leak outside the repository or be coupled with other parts of your code.
- Event-Driven architecture helps with communication. It is about propagating changes and maintain systems decoupled each other. Not about persistence.
- Decoupling matters. Even if you are using all three approaches, they should remain loosely coupled. A change in your event publishing strategy should not require changes to your domain model.
- The Application Service is your transactional boundary. It defines the atomic scope of a use case, ensuring all related changes happen together, or not at all.
I hope this article gave you a clearer mental model of how concepts like DDD, Event-Sourcing, and Event-Driven relate to each other, and how they can coexist without coupling your code
Also, I wanted to highlight how the design of a system can happen in an incremental way.
As I stated previously, if you are interested in exploring this further, I am considering open-sourcing a more complete example on GitHub, possibly with different implementations in Ruby, Elixir, and Java. Let me know if that is something you would find useful, email me or send a DM on Twitter (now X).
Acknowledgements
Thanks to Matteo and Piero for the time spent together in our book club sessions, and for all their feedback while I was writing this article.